下載所需要的庫
pip install requests beautifulsoup4
程式碼
import requests
from bs4 import BeautifulSoup
# 目標網頁URL
url = 'https://www.wikipedia.org/'
# 發送HTTP GET請求
response = requests.get(url)
# 確認請求成功
if response.status_code == 200:
# 解析HTML內容
soup = BeautifulSoup(response.text, 'html.parser')
# 找到所有語言鏈接
languages = soup.find_all('a', {'class': 'link-box'})
# 打印語言鏈接和名稱
for lang in languages:
lang_name = lang.find('strong').text
lang_link = lang['href']
print(f'{lang_name}: {lang_link}')
else:
print(f'無法訪問 {url}, 狀態碼: {response.status_code}')
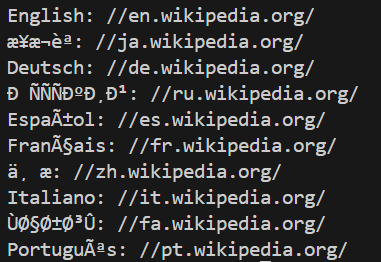
requests:用於發送HTTP請求。
BeautifulSoup:用於解析HTML內容。
使用requests.get(url)發送GET請求,獲取網頁內容。
使用BeautifulSoup解析獲取的HTML內容。
soup = BeautifulSoup(response.text, 'html.parser')將網頁內容轉換為BeautifulSoup對象,方便進行解析。
使用find_all方法找到所有帶有class屬性為link-box的標籤,這些標籤包含了各語言的鏈接。
遍歷提取出的標籤,分別打印語言名稱和鏈接。

